
Common Lisp users are very happy to use
Quicklisp when it comes to
downloading and maintaining dependencies between their own code and the
librairies it is using.

Sometimes I am pointed that when compared to other programming languages
Common Lisp is lacking a lot in the
batteries included area. After having
had to
package about 50 common lisp librairies for debian I can tell you
that I politely disagree with that.
And this post is about the tool and process I use to maintain all those librairies.
Quicklisp is good at ensuring a proper distribution of all those libs it
supports and actually tests that they all compile and load together, so I've
been using it as my upstream for debian packaging purposes. Using Quicklisp
here makes my life much simpler as I can grovel through its metadata and
automate most of the maintenance of my cl related packages.

It's all automated in the
ql-to-deb software which, unsurprisingly, has been
written in Common Lisp itself. It's a kind of a Quicklisp client that will
fetch Quicklisp current list of
releases with version numbers and compare to
the list of managed
packages for debian in order to then
build new version
automatically.
The current workflow I'm using begins with using ql-to-deb is to check
for the work to be done today:
$ /vagrant/build/bin/ql-to-deb check
Fetching "http://beta.quicklisp.org/dist/quicklisp.txt"
Fetching "http://beta.quicklisp.org/dist/quicklisp/2015-04-07/releases.txt"
update: cl+ssl cl-csv cl-db3 drakma esrap graph hunchentoot local-time lparallel nibbles qmynd trivial-backtrace
upload: hunchentoot
After careful manual review of the automatic decision, let's just update
all what check decided would have to be:
$ /vagrant/build/bin/ql-to-deb update
Fetching "http://beta.quicklisp.org/dist/quicklisp.txt"
Fetching "http://beta.quicklisp.org/dist/quicklisp/2015-04-07/releases.txt"
Updating package cl-plus-ssl from 20140826 to 20150302.
see logs in "//tmp/ql-to-deb/logs//cl-plus-ssl.log"
Fetching "http://beta.quicklisp.org/archive/cl+ssl/2015-03-02/cl+ssl-20150302-git.tgz"
Checksum test passed.
File: "/tmp/ql-to-deb/archives/cl+ssl-20150302-git.tgz"
md5: 61d9d164d37ab5c91048827dfccd6835
Building package cl-plus-ssl
Updating package cl-csv from 20140826 to 20150302.
see logs in "//tmp/ql-to-deb/logs//cl-csv.log"
Fetching "http://beta.quicklisp.org/archive/cl-csv/2015-03-02/cl-csv-20150302-git.tgz"
Checksum test passed.
File: "/tmp/ql-to-deb/archives/cl-csv-20150302-git.tgz"
md5: 32f6484a899fdc5b690f01c244cd9f55
Building package cl-csv
Updating package cl-db3 from 20131111 to 20150302.
see logs in "//tmp/ql-to-deb/logs//cl-db3.log"
Fetching "http://beta.quicklisp.org/archive/cl-db3/2015-03-02/cl-db3-20150302-git.tgz"
Checksum test passed.
File: "/tmp/ql-to-deb/archives/cl-db3-20150302-git.tgz"
md5: 578896a3f60f474742f240b703f8c5f5
Building package cl-db3
Updating package cl-drakma from 1.3.11 to 1.3.13.
see logs in "//tmp/ql-to-deb/logs//cl-drakma.log"
Fetching "http://beta.quicklisp.org/archive/drakma/2015-04-07/drakma-1.3.13.tgz"
Checksum test passed.
File: "/tmp/ql-to-deb/archives/drakma-1.3.13.tgz"
md5: 3b548bce10728c7a058f19444c8477c3
Building package cl-drakma
Updating package cl-esrap from 20150113 to 20150302.
see logs in "//tmp/ql-to-deb/logs//cl-esrap.log"
Fetching "http://beta.quicklisp.org/archive/esrap/2015-03-02/esrap-20150302-git.tgz"
Checksum test passed.
File: "/tmp/ql-to-deb/archives/esrap-20150302-git.tgz"
md5: 8b198d26c27afcd1e9ce320820b0e569
Building package cl-esrap
Updating package cl-graph from 20141106 to 20150407.
see logs in "//tmp/ql-to-deb/logs//cl-graph.log"
Fetching "http://beta.quicklisp.org/archive/graph/2015-04-07/graph-20150407-git.tgz"
Checksum test passed.
File: "/tmp/ql-to-deb/archives/graph-20150407-git.tgz"
md5: 3894ef9262c0912378aa3b6e8861de79
Building package cl-graph
Updating package hunchentoot from 1.2.29 to 1.2.31.
see logs in "//tmp/ql-to-deb/logs//hunchentoot.log"
Fetching "http://beta.quicklisp.org/archive/hunchentoot/2015-04-07/hunchentoot-1.2.31.tgz"
Checksum test passed.
File: "/tmp/ql-to-deb/archives/hunchentoot-1.2.31.tgz"
md5: 973eccfef87e81f1922424cb19884d63
Building package hunchentoot
Updating package cl-local-time from 20150113 to 20150407.
see logs in "//tmp/ql-to-deb/logs//cl-local-time.log"
Fetching "http://beta.quicklisp.org/archive/local-time/2015-04-07/local-time-20150407-git.tgz"
Checksum test passed.
File: "/tmp/ql-to-deb/archives/local-time-20150407-git.tgz"
md5: 7be4a31d692f5862014426a53eb1e48e
Building package cl-local-time
Updating package cl-lparallel from 20141106 to 20150302.
see logs in "//tmp/ql-to-deb/logs//cl-lparallel.log"
Fetching "http://beta.quicklisp.org/archive/lparallel/2015-03-02/lparallel-20150302-git.tgz"
Checksum test passed.
File: "/tmp/ql-to-deb/archives/lparallel-20150302-git.tgz"
md5: dbda879d0e3abb02a09b326e14fa665d
Building package cl-lparallel
Updating package cl-nibbles from 20141106 to 20150407.
see logs in "//tmp/ql-to-deb/logs//cl-nibbles.log"
Fetching "http://beta.quicklisp.org/archive/nibbles/2015-04-07/nibbles-20150407-git.tgz"
Checksum test passed.
File: "/tmp/ql-to-deb/archives/nibbles-20150407-git.tgz"
md5: 2ffb26241a1b3f49d48d28e7a61b1ab1
Building package cl-nibbles
Updating package cl-qmynd from 20141217 to 20150302.
see logs in "//tmp/ql-to-deb/logs//cl-qmynd.log"
Fetching "http://beta.quicklisp.org/archive/qmynd/2015-03-02/qmynd-20150302-git.tgz"
Checksum test passed.
File: "/tmp/ql-to-deb/archives/qmynd-20150302-git.tgz"
md5: b1cc35f90b0daeb9ba507fd4e1518882
Building package cl-qmynd
Updating package cl-trivial-backtrace from 20120909 to 20150407.
see logs in "//tmp/ql-to-deb/logs//cl-trivial-backtrace.log"
Fetching "http://beta.quicklisp.org/archive/trivial-backtrace/2015-04-07/trivial-backtrace-20150407-git.tgz"
Checksum test passed.
File: "/tmp/ql-to-deb/archives/trivial-backtrace-20150407-git.tgz"
md5: 762b0acf757dc8a2a6812d2f0f2614d9
Building package cl-trivial-backtrace
Quite simple.
To be totally honnest, I first had a problem with the parser generator
library
esrap wherein the
README documentation changed to be a
README.org
file, and I had to tell my debian packaging about that. See the
0ef669579cf7c07280eae7fe6f61f1bd664d337e commit to
ql-to-deb for details.
What about trying to install those packages locally? That's usually a very
good test. Sometimes some dependencies are missing at the
dpkg command line,
so another
apt-get install -f is needed:
$ /vagrant/build/bin/ql-to-deb install
sudo dpkg -i /tmp/ql-to-deb/cl-plus-ssl_20150302-1_all.deb /tmp/ql-to-deb/cl-csv_20150302-1_all.deb /tmp/ql-to-deb/cl-csv-clsql_20150302-1_all.deb /tmp/ql-to-deb/cl-csv-data-table_20150302-1_all.deb /tmp/ql-to-deb/cl-db3_20150302-1_all.deb /tmp/ql-to-deb/cl-drakma_1.3.13-1_all.deb /tmp/ql-to-deb/cl-esrap_20150302-1_all.deb /tmp/ql-to-deb/cl-graph_20150407-1_all.deb /tmp/ql-to-deb/cl-hunchentoot_1.2.31-1_all.deb /tmp/ql-to-deb/cl-local-time_20150407-1_all.deb /tmp/ql-to-deb/cl-lparallel_20150302-1_all.deb /tmp/ql-to-deb/cl-nibbles_20150407-1_all.deb /tmp/ql-to-deb/cl-qmynd_20150302-1_all.deb /tmp/ql-to-deb/cl-trivial-backtrace_20150407-1_all.deb
(Reading database ... 79689 files and directories currently installed.)
Preparing to unpack .../cl-plus-ssl_20150302-1_all.deb ...
Unpacking cl-plus-ssl (20150302-1) over (20140826-1) ...
Selecting previously unselected package cl-csv.
Preparing to unpack .../cl-csv_20150302-1_all.deb ...
Unpacking cl-csv (20150302-1) ...
Selecting previously unselected package cl-csv-clsql.
Preparing to unpack .../cl-csv-clsql_20150302-1_all.deb ...
Unpacking cl-csv-clsql (20150302-1) ...
Selecting previously unselected package cl-csv-data-table.
Preparing to unpack .../cl-csv-data-table_20150302-1_all.deb ...
Unpacking cl-csv-data-table (20150302-1) ...
Selecting previously unselected package cl-db3.
Preparing to unpack .../cl-db3_20150302-1_all.deb ...
Unpacking cl-db3 (20150302-1) ...
Preparing to unpack .../cl-drakma_1.3.13-1_all.deb ...
Unpacking cl-drakma (1.3.13-1) over (1.3.11-1) ...
Preparing to unpack .../cl-esrap_20150302-1_all.deb ...
Unpacking cl-esrap (20150302-1) over (20150113-1) ...
Preparing to unpack .../cl-graph_20150407-1_all.deb ...
Unpacking cl-graph (20150407-1) over (20141106-1) ...
Preparing to unpack .../cl-hunchentoot_1.2.31-1_all.deb ...
Unpacking cl-hunchentoot (1.2.31-1) over (1.2.29-1) ...
Preparing to unpack .../cl-local-time_20150407-1_all.deb ...
Unpacking cl-local-time (20150407-1) over (20150113-1) ...
Preparing to unpack .../cl-lparallel_20150302-1_all.deb ...
Unpacking cl-lparallel (20150302-1) over (20141106-1) ...
Preparing to unpack .../cl-nibbles_20150407-1_all.deb ...
Unpacking cl-nibbles (20150407-1) over (20141106-1) ...
Preparing to unpack .../cl-qmynd_20150302-1_all.deb ...
Unpacking cl-qmynd (20150302-1) over (20141217-1) ...
Preparing to unpack .../cl-trivial-backtrace_20150407-1_all.deb ...
Unpacking cl-trivial-backtrace (20150407-1) over (20120909-2) ...
Setting up cl-plus-ssl (20150302-1) ...
dpkg: dependency problems prevent configuration of cl-csv:
cl-csv depends on cl-interpol; however:
Package cl-interpol is not installed.
dpkg: error processing package cl-csv (--install):
dependency problems - leaving unconfigured
dpkg: dependency problems prevent configuration of cl-csv-clsql:
cl-csv-clsql depends on cl-csv; however:
Package cl-csv is not configured yet.
dpkg: error processing package cl-csv-clsql (--install):
dependency problems - leaving unconfigured
dpkg: dependency problems prevent configuration of cl-csv-data-table:
cl-csv-data-table depends on cl-csv; however:
Package cl-csv is not configured yet.
dpkg: error processing package cl-csv-data-table (--install):
dependency problems - leaving unconfigured
Setting up cl-db3 (20150302-1) ...
Setting up cl-drakma (1.3.13-1) ...
Setting up cl-esrap (20150302-1) ...
Setting up cl-graph (20150407-1) ...
Setting up cl-local-time (20150407-1) ...
Setting up cl-lparallel (20150302-1) ...
Setting up cl-nibbles (20150407-1) ...
Setting up cl-qmynd (20150302-1) ...
Setting up cl-trivial-backtrace (20150407-1) ...
Setting up cl-hunchentoot (1.2.31-1) ...
Errors were encountered while processing:
cl-csv
cl-csv-clsql
cl-csv-data-table
Let's make sure that our sid users will be happy with the update here:
$ sudo apt-get install -f
Reading package lists... Done
Building dependency tree
Reading state information... Done
Correcting dependencies... Done
The following packages were automatically installed and are no longer required:
g++-4.7 git git-man html2text libaugeas-ruby1.8 libbind9-80
libclass-isa-perl libcurl3-gnutls libdns88 libdrm-nouveau1a
libegl1-mesa-drivers libffi5 libgraphite3 libgssglue1 libisc84 libisccc80
libisccfg82 liblcms1 liblwres80 libmpc2 libopenjpeg2 libopenvg1-mesa
libpoppler19 librtmp0 libswitch-perl libtiff4 libwayland-egl1-mesa luatex
openssh-blacklist openssh-blacklist-extra python-chardet python-debian
python-magic python-pkg-resources python-six ttf-dejavu-core ttf-marvosym
Use 'apt-get autoremove' to remove them.
The following extra packages will be installed:
cl-interpol
The following NEW packages will be installed:
cl-interpol
0 upgraded, 1 newly installed, 0 to remove and 51 not upgraded.
3 not fully installed or removed.
Need to get 20.7 kB of archives.
After this operation, 135 kB of additional disk space will be used.
Do you want to continue? [Y/n]
Get:1 http://ftp.fr.debian.org/debian/ sid/main cl-interpol all 0.2.1-2 [20.7 kB]
Fetched 20.7 kB in 0s (84.5 kB/s)
debconf: unable to initialize frontend: Dialog
debconf: (Dialog frontend will not work on a dumb terminal, an emacs shell buffer, or without a controlling terminal.)
debconf: falling back to frontend: Readline
Selecting previously unselected package cl-interpol.
(Reading database ... 79725 files and directories currently installed.)
Preparing to unpack .../cl-interpol_0.2.1-2_all.deb ...
Unpacking cl-interpol (0.2.1-2) ...
Setting up cl-interpol (0.2.1-2) ...
Setting up cl-csv (20150302-1) ...
Setting up cl-csv-clsql (20150302-1) ...
Setting up cl-csv-data-table (20150302-1) ...
All looks fine, time to
sign those packages. There's a trick here, where you
want to be sure you're using a GnuPG setup that allows you to enter your
passphrase only once, see
ql-to-deb vm setup for details, and the usual
documentations about all that if you're interested into the details.
$ /vagrant/build/bin/ql-to-deb sign
signfile /tmp/ql-to-deb/cl-plus-ssl_20150302-1.dsc 60B1CB4E
signfile /tmp/ql-to-deb/cl-plus-ssl_20150302-1_amd64.changes 60B1CB4E
Successfully signed dsc and changes files
signfile /tmp/ql-to-deb/cl-csv_20150302-1.dsc 60B1CB4E
signfile /tmp/ql-to-deb/cl-csv_20150302-1_amd64.changes 60B1CB4E
Successfully signed dsc and changes files
signfile /tmp/ql-to-deb/cl-db3_20150302-1.dsc 60B1CB4E
signfile /tmp/ql-to-deb/cl-db3_20150302-1_amd64.changes 60B1CB4E
Successfully signed dsc and changes files
signfile /tmp/ql-to-deb/cl-drakma_1.3.13-1.dsc 60B1CB4E
signfile /tmp/ql-to-deb/cl-drakma_1.3.13-1_amd64.changes 60B1CB4E
Successfully signed dsc and changes files
signfile /tmp/ql-to-deb/cl-esrap_20150302-1.dsc 60B1CB4E
signfile /tmp/ql-to-deb/cl-esrap_20150302-1_amd64.changes 60B1CB4E
Successfully signed dsc and changes files
signfile /tmp/ql-to-deb/cl-graph_20150407-1.dsc 60B1CB4E
signfile /tmp/ql-to-deb/cl-graph_20150407-1_amd64.changes 60B1CB4E
Successfully signed dsc and changes files
signfile /tmp/ql-to-deb/hunchentoot_1.2.31-1.dsc 60B1CB4E
signfile /tmp/ql-to-deb/hunchentoot_1.2.31-1_amd64.changes 60B1CB4E
Successfully signed dsc and changes files
signfile /tmp/ql-to-deb/cl-local-time_20150407-1.dsc 60B1CB4E
signfile /tmp/ql-to-deb/cl-local-time_20150407-1_amd64.changes 60B1CB4E
Successfully signed dsc and changes files
signfile /tmp/ql-to-deb/cl-lparallel_20150302-1.dsc 60B1CB4E
signfile /tmp/ql-to-deb/cl-lparallel_20150302-1_amd64.changes 60B1CB4E
Successfully signed dsc and changes files
signfile /tmp/ql-to-deb/cl-nibbles_20150407-1.dsc 60B1CB4E
signfile /tmp/ql-to-deb/cl-nibbles_20150407-1_amd64.changes 60B1CB4E
Successfully signed dsc and changes files
signfile /tmp/ql-to-deb/cl-qmynd_20150302-1.dsc 60B1CB4E
signfile /tmp/ql-to-deb/cl-qmynd_20150302-1_amd64.changes 60B1CB4E
Successfully signed dsc and changes files
signfile /tmp/ql-to-deb/cl-trivial-backtrace_20150407-1.dsc 60B1CB4E
signfile /tmp/ql-to-deb/cl-trivial-backtrace_20150407-1_amd64.changes 60B1CB4E
Successfully signed dsc and changes files
Ok, with all tested and signed, it's time we
upload our packages on debian
servers for our dear debian users to be able to use newer and better
versions of their beloved Common Lisp librairies:
$ /vagrant/build/bin/ql-to-deb upload
Trying to upload package to ftp-master (ftp.upload.debian.org)
Checking signature on .changes
gpg: Signature made Sat 02 May 2015 05:06:48 PM MSK using RSA key ID 60B1CB4E
gpg: Good signature from "Dimitri Fontaine <dim@tapoueh.org>"
Good signature on /tmp/ql-to-deb/cl-plus-ssl_20150302-1_amd64.changes.
Checking signature on .dsc
gpg: Signature made Sat 02 May 2015 05:06:46 PM MSK using RSA key ID 60B1CB4E
gpg: Good signature from "Dimitri Fontaine <dim@tapoueh.org>"
Good signature on /tmp/ql-to-deb/cl-plus-ssl_20150302-1.dsc.
Uploading to ftp-master (via ftp to ftp.upload.debian.org):
Uploading cl-plus-ssl_20150302-1.dsc: done.
Uploading cl-plus-ssl_20150302.orig.tar.gz: done.
Uploading cl-plus-ssl_20150302-1.debian.tar.xz: done.
Uploading cl-plus-ssl_20150302-1_all.deb: done.
Uploading cl-plus-ssl_20150302-1_amd64.changes: done.
Successfully uploaded packages.
Of course the same text or abouts is then repeated for all the other packages.
Enjoy using Common Lisp in debian!

Oh and remember, the only reason I've written
ql-to-deb and signed myself up
to maintain those upteens Common Lisp librairies as debian package is to be
able to properly package
pgloader in debian, as you can see at
https://packages.debian.org/sid/pgloader and in particular in the
Other
Packages Related to pgloader section of the debian source package for
pgloader at
https://packages.debian.org/source/sid/pgloader.
That level of effort is done to ensure that we respect the
Debian Social Contract wherein debian ensures its users that it's possible
to rebuild anything from sources as found in the debian repositories.
 Allison Lortie has provoked a lot of comment with her blog post on
Allison Lortie has provoked a lot of comment with her blog post on


 What happened in the
What happened in the 
 Recently, Eric Raymond, famous for is
Recently, Eric Raymond, famous for is  The arguments are quite easy to summarize: The meritocracy party proposes that One s contribution should only be evaluated based on the content and the quality , while the SJW party asserts that in case the submitter as from a minority group, in particular everyone outside the white straight group, the contribution has to be accepted with higher probability (or without discussion) to ensure equality.
(Added here for clarification: A SJW is someone who puts the agenda of anti-genderization and anti-biasization (nice word) above all other objectives, often by quoting scientific results on existing and not deniable bias)
Well, I am a scientist, and I can tell you just one thing: I simply don t give a shit for whether someone is white, black, red, green, red, straight, gay, a Rastafari or
The arguments are quite easy to summarize: The meritocracy party proposes that One s contribution should only be evaluated based on the content and the quality , while the SJW party asserts that in case the submitter as from a minority group, in particular everyone outside the white straight group, the contribution has to be accepted with higher probability (or without discussion) to ensure equality.
(Added here for clarification: A SJW is someone who puts the agenda of anti-genderization and anti-biasization (nice word) above all other objectives, often by quoting scientific results on existing and not deniable bias)
Well, I am a scientist, and I can tell you just one thing: I simply don t give a shit for whether someone is white, black, red, green, red, straight, gay, a Rastafari or  Eric Raymond, author of
Eric Raymond, author of 
 Following the tradition of
Following the tradition of  Found at the
Found at the  After using haproxy at work for some time I realized that it can be configured for a lot of things, for example: it knows about SNI (on ssl is the method we use to know what host the client is trying to reach so that we know what certificate to present and thus we can multiplex several virtual hosts on the same ssl IP:port) and it also knows how to make transparent proxy connections (the connections go through haproxy but the ending server will think they are arriving directly from the client, as it will see the client's IP as the source IP of the packages).With this two little features, which are available on haproxy 1.5 (Jessie's version has them all), I thought I could give it a try to substitute sslh with haproxy giving me a lot of possibilities that sslh cannot do.Having this in mind I thought I could multiplex several ssl services, not only https but also openvpn or similar, on the 443 port and also allow this services to arrive transparently to the final server. Thus what I wanted was not to mimic sslh (which can be done with haproxy) but to get the semantic I needed, which is similar to sslh but with more power and with a little different behaviour, cause I liked it that way.There is however one caveat that I don't like about this setup and it is that to achieve the transparency one has to run haproxy as root, which is not really something one likes :-( so, having transparency is great, but we'll be taking some risks here which I personally don't like, to me it isn't worth it.Anyway, here is the setup, it basically consists of a setup on haproxy but if we want transparency we'll have to add to it a routing and iptables setup, I'll describe here the whole setupHere is what you need to define on /etc/haproxy/haproxy.cfg:frontend ft_ssl bind 192.168.0.1:443 mode tcp option tcplog tcp-request inspect-delay 5s tcp-request content accept if req_ssl_hello_type 1 acl sslvpn req_ssl_sni -i vpn.example.net use_backend bk_sslvpn if sslvpn use_backend bk_web if req_ssl_sni -m found default_backend bk_ssh backend bk_sslvpn mode tcp source 0.0.0.0 usesrc clientip server srvvpn vpnserver:1194 backend bk_web mode tcp source 0.0.0.0 usesrc clientip server srvhttps webserver:443 backend bk_ssh mode tcp source 0.0.0.0 usesrc clientip server srvssh sshserver:22 An example of a transparent setup can be found
After using haproxy at work for some time I realized that it can be configured for a lot of things, for example: it knows about SNI (on ssl is the method we use to know what host the client is trying to reach so that we know what certificate to present and thus we can multiplex several virtual hosts on the same ssl IP:port) and it also knows how to make transparent proxy connections (the connections go through haproxy but the ending server will think they are arriving directly from the client, as it will see the client's IP as the source IP of the packages).With this two little features, which are available on haproxy 1.5 (Jessie's version has them all), I thought I could give it a try to substitute sslh with haproxy giving me a lot of possibilities that sslh cannot do.Having this in mind I thought I could multiplex several ssl services, not only https but also openvpn or similar, on the 443 port and also allow this services to arrive transparently to the final server. Thus what I wanted was not to mimic sslh (which can be done with haproxy) but to get the semantic I needed, which is similar to sslh but with more power and with a little different behaviour, cause I liked it that way.There is however one caveat that I don't like about this setup and it is that to achieve the transparency one has to run haproxy as root, which is not really something one likes :-( so, having transparency is great, but we'll be taking some risks here which I personally don't like, to me it isn't worth it.Anyway, here is the setup, it basically consists of a setup on haproxy but if we want transparency we'll have to add to it a routing and iptables setup, I'll describe here the whole setupHere is what you need to define on /etc/haproxy/haproxy.cfg:frontend ft_ssl bind 192.168.0.1:443 mode tcp option tcplog tcp-request inspect-delay 5s tcp-request content accept if req_ssl_hello_type 1 acl sslvpn req_ssl_sni -i vpn.example.net use_backend bk_sslvpn if sslvpn use_backend bk_web if req_ssl_sni -m found default_backend bk_ssh backend bk_sslvpn mode tcp source 0.0.0.0 usesrc clientip server srvvpn vpnserver:1194 backend bk_web mode tcp source 0.0.0.0 usesrc clientip server srvhttps webserver:443 backend bk_ssh mode tcp source 0.0.0.0 usesrc clientip server srvssh sshserver:22 An example of a transparent setup can be found 

 Problem description: One of my customers had a problem with their
Problem description: One of my customers had a problem with their 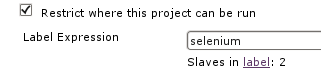 TIP 1: Visiting $JENKINS_SERVER/label/$label/ provides a list of slaves that provide that given $label (as well as list of projects that use $label in their configuration), like:
TIP 1: Visiting $JENKINS_SERVER/label/$label/ provides a list of slaves that provide that given $label (as well as list of projects that use $label in their configuration), like:

 This is what we can use to gradually upgrade from the old Iceweasel version to the new one by keeping a given set of slaves at the old Iceweasel version while we re upgrading other nodes to the new Iceweasel version (same for the selenium-server version which we want to also control). We can include the version number of the Iceweasel and selenium-server packages inside the labels we announce through the swarm slaves, with something like:
This is what we can use to gradually upgrade from the old Iceweasel version to the new one by keeping a given set of slaves at the old Iceweasel version while we re upgrading other nodes to the new Iceweasel version (same for the selenium-server version which we want to also control). We can include the version number of the Iceweasel and selenium-server packages inside the labels we announce through the swarm slaves, with something like:
 Whereas the development selenium job can point to the slaves providing Iceweasel v24, so it will be executed on slave selenium-client1 here:
Whereas the development selenium job can point to the slaves providing Iceweasel v24, so it will be executed on slave selenium-client1 here:
 This setup allowed us to work on the selenium Ruby tests while not conflicting with any production build pipeline. By the time I m writing about this setup we ve already finished the migration to support Iceweasel v24 and the infrastructure is ready for further Iceweasel and selenium-server upgrades.
This setup allowed us to work on the selenium Ruby tests while not conflicting with any production build pipeline. By the time I m writing about this setup we ve already finished the migration to support Iceweasel v24 and the infrastructure is ready for further Iceweasel and selenium-server upgrades.
 Thanks to bernat on #debian @ irc.debian.org for
Thanks to bernat on #debian @ irc.debian.org for